BUAA OO Unit3 基于规格的层次化设计
前言
这是2021级BUAA 面向对象课程第三单元实验——基于规格的层次化设计的博客总结。
架构设计
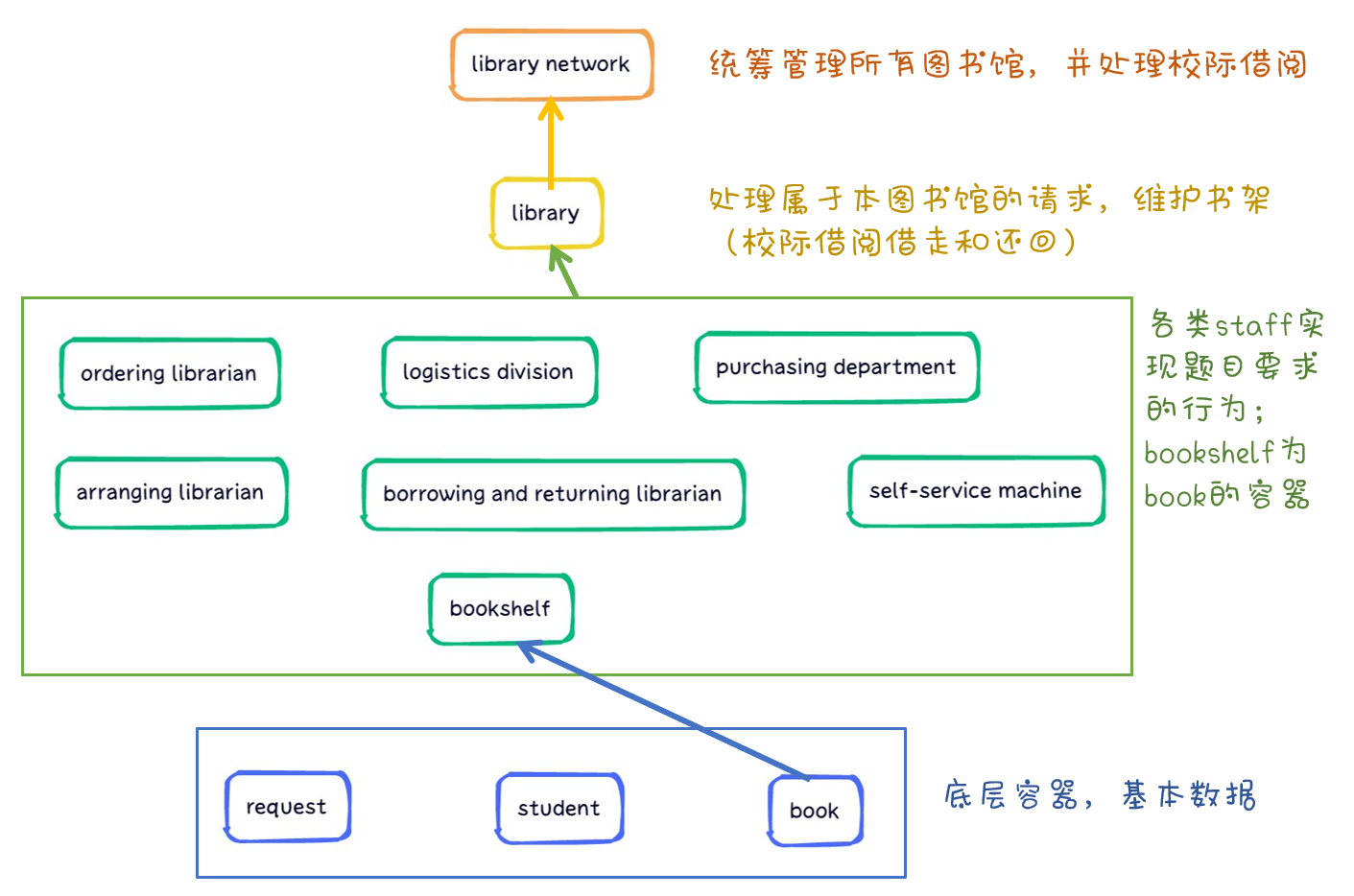
本单元作业需要根据 JML 规格描述实现一个社交关系模拟系统,需要阅读JML,实现高效图算法以及异常处理。下面主要从各单元图算法实现进行分析。
首先阅读 JML 发现许多方法需要通过 id 得到 person ,容易想到用 HashMap 进行存储。
hw9 —— 查询连通性和三角形关系数
通过阅读 JML 发现在 Network 类的 isCircle 方法查询给定两点的连通性, queryBlockSum 方法查询连通块数量,这显然可以通过并查集实现。为了体现类的封装性,我在 DisjointSet 类内实现了并查集的相关操作。
三角形关系数是指三人互为熟人。如果暴力求解,时间复杂度为 ,显然会 TLE。实际上这可以通过加边时的动态维护实现:
-
在每次
addRelation时,枚举除了id1和id2的所有人,若他们与二人分别有边,则关系数加1。 -
我们还可以进一步优化上述 O(N) 的维护算法。我们通过
BitSet维护每个Person的Acquaintance,那么如果要得到二人共同的熟人只需要与一下。另外,由于Person的id仅保证在int范围内,需要给每个Person一个number属性进行离散化操作。public class MyPerson implements Person {
private static int tot = 0; // 共有多少人
private int number; // 本人是第几个
private BitSet bitSet; // 记录关系
public MyPerson(int id, String name, int age) {
...
this.number = tot++;
this.bitSet = new BitSet();
}
public void addAcquaintance(Person person, int value) {
...
bitSet.set(((MyPerson)person).getNumber());
}
}
public class MyNetwork implements Network {
public void addRelation(int id1, int id2, int value) {
BitSet bitSet = (BitSet) ((MyPerson) getPerson(id1)).getBitSet().clone();
bitSet.and(((MyPerson) getPerson(id2)).getBitSet());
tripSum += bitSet.cardinality();
}
}
hw10 —— 有删边的连通性维护和动态维护最大值
在 modifyRelation 中,当修改后的 ,两人就不再是熟人了。然而并查集并不支持删边操作。此时我认为时间复杂度合适并且实现简单的是 写时复制的并查集,当进行了删边操作时,不选择立即重建并查集,而是标记 removeFlag = true;在需要查询连通性时,检查 removeFlag ,若为 true ,则重建并查集。另外当 removeFlag = false 时,并查集失效,此时不需要在 addRelation 中维护并查集。
在 queryBestAcquaintance 方法中,需要查询该 Person 的所有 Acquaintance 中 value 最大的一位。这通过在新增或修改 value 过程中动态维护。当该 person 的 bestAcquaintance 的 value 减少或 acquaintance 删除时,遍历一遍所有 Acquaintance 维护。至于 queryCoupleSum 方法查询双方都是对方 value 最大的 acquaintance 则直接 遍历即可。
public class MyPerson implements Person { |
hw11 —— 查询包含某点的最小环
在本次作业中 message 类型更多样,这些操作照着 JML 实现,一般不会有问题。
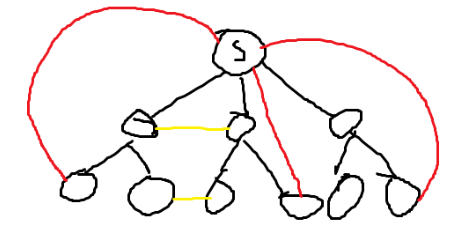
值得关注的是 queryLeastMoments 方法,查询包含某个点的最小环。首先想到的是 Floyed 算法,时间复杂度 ,必然 TLE。然后想到了删边的 Dijkstra 做法,时间复杂度有点危险(确实强测点会寄一个)。然后我学习了 Dijkstra+并查集 做法:
-
枚举要求经过的点 s;
-
用 Dijkstra 求单源最短路;
-
包含点s的最小环即为s到其余点的最短路的边加上一条不是最短路的边(该边有两种情况,见下图)。
实现细节可见代码:
private int[] pre; |
测试
测试方法
白箱测试是指根据程序内部逻辑测试程序,检查程序中的每条通路是否按照预定要求正确工作(即穷举路径),要求测试者了解程序结构和处理过程。
- 语句覆盖(Statement Coverage):确保每个代码语句都至少执行一次。
- 分支覆盖(Branch Coverage):确保每个分支(如if语句中的条件判断)的两个可能结果(真和假)都至少执行一次。
- 条件覆盖(Condition Coverage):确保每个条件的所有可能取值都被测试到。
- 路径覆盖(Path Coverage):确保每个可能的路径都被覆盖到。
- 边界值测试(Boundary Value Testing):测试边界值和特殊情况,例如最小和最大输入值、边界条件和异常情况。
黑箱测试 是指根据功能需求测试程序是否按照预期工作,基于系统的需求规格和功能规范来设计测试用例,并通过输入不同的数据和条件,观察系统的输出是否符合预期(即穷举输入),而不涉及程序的内部结构和内容特性。
- 等价类划分(Equivalence Partitioning):将输入数据划分为等价类,每个等价类中的数据被认为具有相同的测试行为,从每个等价类中选择代表性的测试数据。
- 边界值分析(Boundary Value Analysis):测试输入数据的边界情况,例如最小值、最大值以及接近边界的值,因为边界处往往容易出现错误。
- 错误推测(Error Guessing):基于测试人员的经验和直觉,猜测可能存在的错误,并设计测试用例以验证这些猜测。
- 随机测试(Random Testing):使用随机生成的测试数据进行测试,以发现潜在的错误和异常情况。
- 用户场景测试(User Scenario Testing):基于用户的实际使用场景和预期行为,设计测试用例来模拟用户的操作和交互。
单元测试 是针对程序模块(软件设计的最小单位)来进行正确性检验的测试工作。它的目的是在开发过程中尽早发现代码中的缺陷,并确保每个功能模块都能够独立地正常运行。
- 高度自动化:单元测试通常是自动化的,开发人员编写测试代码,并使用测试框架执行测试。这样可以快速、方便地运行测试,并重复执行以确保稳定性。
- 针对最小单元:单元测试的重点是测试代码的最小可测试单元,通常是一个函数或方法。通过隔离单个功能模块,可以更容易地定位和修复问题。
- 独立性:每个单元测试应该是相互独立的,不依赖于其他单元测试的运行结果。这种独立性有助于更好地定位和排查问题,也使得测试更加可靠和可重复。
- 快速执行:由于单元测试关注最小单元,测试执行速度通常很快。这样可以迅速获得反馈,使开发人员能够快速修复问题。
- 提高代码质量:通过编写单元测试,开发人员可以更好地理解功能模块的需求和预期行为。这有助于提高代码质量、降低bug出现的概率,并促使开发人员编写更可靠、健壮的代码。
功能测试 是测试软件功能是否符合需求,通常采用黑箱测试方法。
集成测试 是软件测试的一种方法,用于验证不同组件、模块或子系统之间的集成是否正确、协同合作,并能够产生预期的结果。它旨在检测和解决在组件集成过程中可能出现的问题。在集成测试中,被测试的软件系统已经通过单元测试对各个组件进行了测试,并且这些组件已经通过了单元测试阶段。集成测试的目标是验证组件之间的接口、数据传递和交互是否正常,以及确保整个系统在集成后能够正确运行。
压力测试 是软件测试的一种方法,用于评估系统在超出正常工作负载条件下的性能和稳定性。它通过模拟系统面临的高负载、大数据量或高并发等情况,检查系统在这些极端情况下的表现和响应。压力测试的主要目标是找出系统的瓶颈、性能问题和资源耗尽情况,并评估系统在负载增加时是否能够满足性能要求。这种测试方法可以揭示系统的弱点、性能限制和潜在的故障,为系统的优化和调整提供指导。
回归测试 软件测试的一种方法,用于确认在进行软件修改、修复或增加新功能后,原有功能是否仍然正常工作,以及新的修改是否引入了新的错误或问题。当对软件进行修改时,无论是修复缺陷、添加新功能还是进行系统配置变更,都存在可能引入新的错误或导致原有功能出现问题的风险。回归测试的目的是在进行修改后,重新运行既有的测试用例,以验证软件系统在修改后的版本中是否仍然具有预期的行为。
测试过程
由于本单元作业的实现并不复杂,白箱测试我通过人工逻辑分析与检查替代,在完成代码编写后,先浏览一遍,和 JML 比对,检查是否有疏忽,这能解决 60% 的 bug。
然后编写测试用例,主要通过生成随机性和大数据量的测试用例来完成黑箱测试,缺点是这样仍然难以保证覆盖性。
规格与实现分离
规格与实现分离是指将规格说明与具体实现分开,以实现更好的灵活性、可维护性和可扩展性。通过本单元作业,我认识到了规格与实现分离的一些好处:
- 灵活性和可维护性。如果需要对系统进行功能增加、修改或优化,只需更改实现部分而不影响规格,从而降低了修改带来的风险,并提高了系统的灵活性和可维护性。通过阅读 JML 规格,可以很清晰地发现哪些实现需要修改,提高了效率。
- 可测试性。根据规格编写测试用例,可以验证实现是否符合规格要求,从而提高软件的质量和可靠性。本单元作业同学们的架构比较相似,降低了互测阅读源码寻找bug的复杂性。
在 hw11 中,我在做 Dijkstra 使用 int dist[people.length] (得益于离散化操作,不需要使用 HashMap), 但是 run 类调用 addPerson 方法时,即使该 person 非法,我也赋予了他 myID ,导致 people.size != tot。
在我的实现中,规格与实现分离的很好的一个体现就是在求连通性时新增了 DisjointSet 类实现并查集相关操作,也让后续维护更清晰。
OK测试方法
OK测试对于检验代码实现与规格的一致性的作用:
- 通过对比代码实现与规格要求,可以发现代码中的错误和缺陷。
- 确保代码实现了规格中定义的所有功能,并且没有遗漏或错误地实现了某些功能。
不过,我在本单元作业中对其感触不深,可能对我最大的用处就是在写OKTest时回忆检测的方法对象是否完全实现。因为理论上来说,OK测试应该调用我实现的方法判断数据处理前后是否满足规格,但显然这样课程组很难测试,于是课程组采用传入输入输出数据来判断,于是我的OKTest实现就变成了这样,我感觉和OK测试的初衷没啥关系:
public int deleteColdEmojiOKTest(int limit, ArrayList<HashMap<Integer, Integer>> beforeData, |
学习体会
本单元我觉得重点不在于代码的实现,而是基于规格的层次化设计,掌握了数据、方法、类的规格及其设计方法和基于规格的测试方法。编写 JML 规格可以提高设计的正确性和可迭代性,我认为这钟设计方式在未来大型项目团队合作中非常需要。